The AI Efficiency Playbook: Which Model Wins for Every Task (May 2026)
Tiger Tracks · Eye of the Tiger · AI & Automation · May 2026
Tiger Tracks · Eye of the Tiger · Technology Intelligence · May 2026
The generative AI market has matured past the point where a single model can serve as a universal solution. In 2026, the question is no longer which AI is best, but rather which AI is best for a specific workflow. The rapid release cycle from Anthropic, OpenAI, and Google has created a fragmented landscape of specialized tools. Power users and enterprise teams who attempt to run all operations through a single interface are leaving both performance and capital on the table.
This intelligence briefing analyzes the current state of frontier models, unpacks the recent Claude Opus update cycle, and provides a definitive guide to the optimal tools for specific business and creative applications. The analysis covers nine major model families, six image generation platforms, and eight distinct use case categories.
1. The Claude Opus Progression: From 4.6 to 4.8
Anthropic's release cadence in early 2026 caused significant friction among power users. Claude Opus 4.6, released in February, established a high watermark for reliability and precision, particularly for long-context retrieval where it scored 91.9 percent on standardized benchmarks. When Opus 4.7 launched in April, it brought a 13 percent improvement in coding benchmarks and a 3x boost in visual performance. Yet the update was met with immediate user backlash.
The issue was twofold. First, Opus 4.7 suffered a severe regression in long-context retrieval, dropping from 91.9 percent to just 59.2 percent. Second, users experienced significant latency spikes. Tasks that completed in seconds on 4.6 began taking minutes, leading many developers and writers to actively downgrade back to the older model. Community forums filled with reports of sessions taking five to seven minutes to return responses, and token burn rates that were measurably higher than on 4.6.
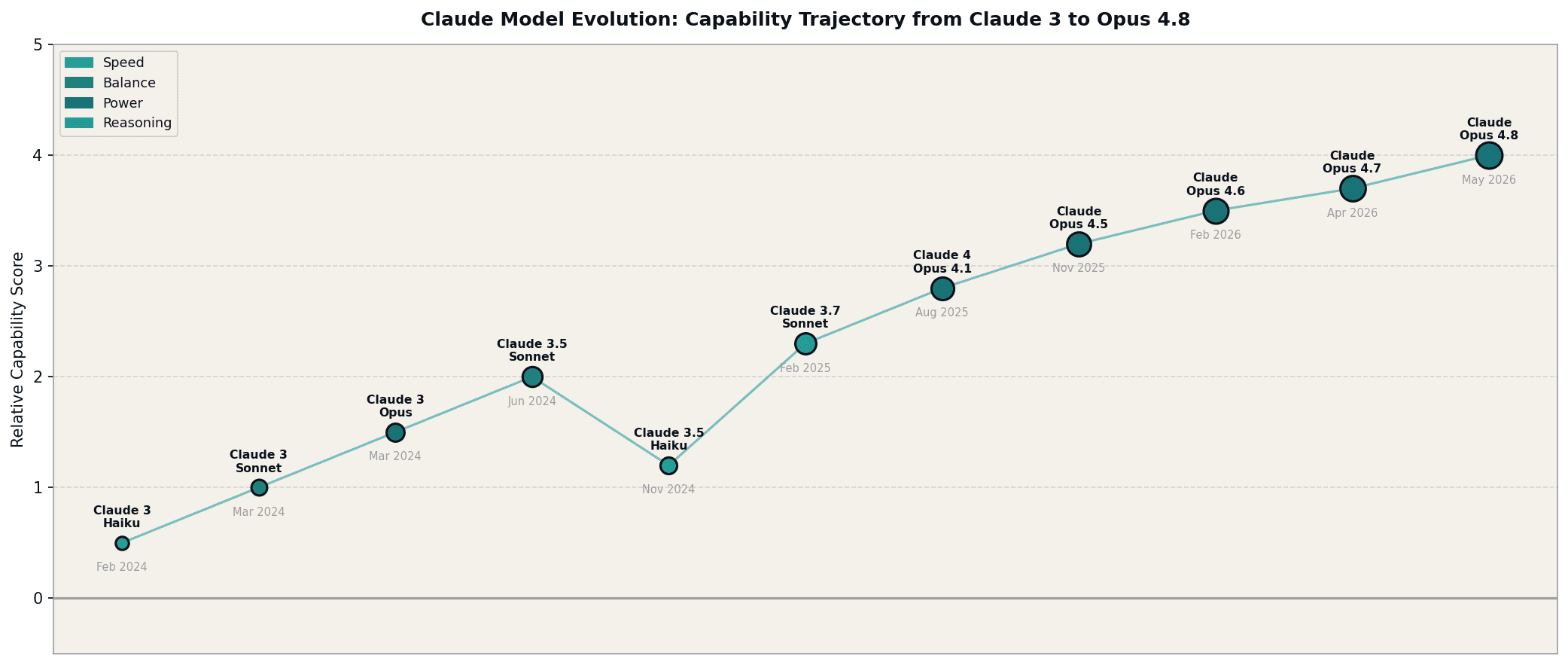
Figure 1: The capability trajectory of Anthropic's models from Claude 3 Haiku through Opus 4.8, showing the rapid succession of the Opus 4 series and the resolution of the 4.7 latency issues.
The release of Claude Opus 4.8 on May 28, 2026 functions as a necessary course correction. It retains the vision and coding improvements introduced in 4.7 while resolving the speed and retrieval bottlenecks that defined the 4.7 experience. Opus 4.8 now leads the Super-Agent benchmarks, completing every evaluated case end-to-end. It also exceeds both Opus 4.7 and GPT-5.5 in Online-Mind2Web performance, a benchmark that tests real-world web navigation and task completion.
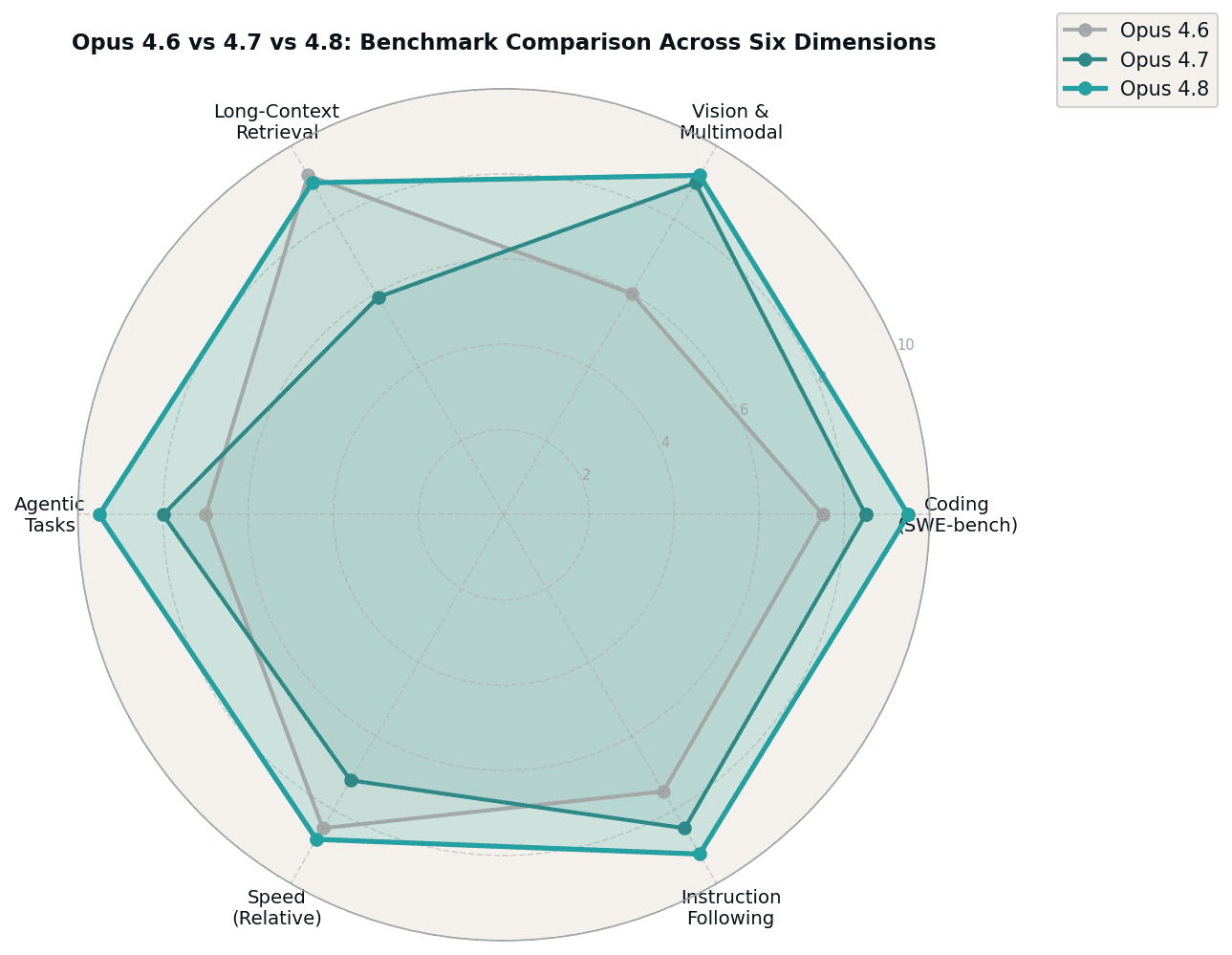
Figure 2: Benchmark radar comparing Opus 4.6, 4.7, and 4.8 across six dimensions. Note the long-context retrieval regression in 4.7 and its restoration in 4.8, alongside the coding and vision gains carried forward from 4.7.
| Model | Release | Best For | Speed (TPS) | Key Strength | Key Weakness |
|---|---|---|---|---|---|
| Claude Haiku 3 | Feb 2024 | High-volume, fast tasks | 123 | Lowest cost, fastest response | Limited reasoning depth |
| Claude Haiku 3.5 | Nov 2024 | Quick queries, real-time apps | 65 | Speed + quality balance | Not suited for complex tasks |
| Claude Sonnet 3.5 | Jun 2024 | General enterprise use | 72 | Balanced cost and capability | Outpaced by Sonnet 4.6 |
| Claude Sonnet 4.6 | 2026 | Coding at scale, daily work | 68 | 79.6% SWE-bench, 60% cheaper than Opus | Lacks Opus depth for complex reasoning |
| Claude Opus 4.6 | Feb 2026 | Long-context tasks, daily writing | 30 | Best long-context retrieval (91.9%) | Slower than Haiku/Sonnet |
| Claude Opus 4.7 | Apr 2026 | Coding, vision tasks | 25 | Best coding and visual benchmarks | Speed regression, retrieval drop to 59.2% |
| Claude Opus 4.8 | May 2026 | Agentic tasks, deep analysis | 35 | Best overall: speed + coding + retrieval restored | Premium inference cost |
2. The Right Model for the Right Task
The most efficient teams in 2026 operate with a multi-model strategy. Selecting the right tool requires balancing intelligence, speed, and inference cost against the specific requirements of the task. The following analysis covers the eight most common professional use cases and identifies the optimal model for each.
Writing and Communication
For email drafting, internal communications, and nuanced copywriting, Claude Opus 4.8 remains the category leader. Anthropic's models consistently produce more human-sounding prose with better tonal variation than their competitors. The writing quality is particularly evident in longer-form content where tonal consistency across paragraphs matters. When volume and speed are prioritized over deep nuance, Claude Haiku 4.6 provides an optimal balance of quality and cost efficiency, handling thousands of short-form outputs at a fraction of Opus pricing.
Financial Analysis and Structured Data
OpenAI's GPT-5.5 leads the market in structured professional work. It currently scores 84.9 percent on the GDPval benchmark, which tests performance across 44 real-world occupations including finance, legal research, and product management. For financial modeling and tasks requiring rigid structural adherence, GPT-5.5 outperforms Claude. If the analysis requires reading complex charts or parsing massive PDF archives, Google's Gemini 2.5 Pro offers superior multimodal integration and a larger effective context window.
Coding and Development
The coding landscape is split between raw model capability and integrated environments. Claude Code, powered by Opus 4.8, currently leads the CursorBench evaluations at 70 percent. For developers seeking an integrated experience, Cursor remains the premier IDE. For teams operating with strict inference budgets, Claude Sonnet 4.6 delivers nearly 80 percent of Opus's coding performance at a 60 percent discount. DeepSeek V3.2 is the strongest open-source option, offering competitive reasoning at inference costs as low as $0.04 per million tokens.
Research and Fact-Checking
Perplexity AI is consistently underrated in this category. It is not simply a chatbot; it is a search-augmented reasoning engine that synthesizes real-time web sources into structured answers with citations. For research tasks that require current information, Perplexity outperforms any static LLM. For deep analytical synthesis of existing knowledge, Gemini 2.5 Pro's combination of massive context and Google Search integration makes it the strongest alternative.
Quick Queries and Casual Conversation
Speed and cost dominate this category. Claude Haiku 4.6 at 65 tokens per second and Gemini Flash 2.5 at 100 tokens per second are the clear leaders. For users already embedded in the Google ecosystem, Gemini Flash offers the additional advantage of native integration with Gmail, Docs, and Drive. ChatGPT with GPT-4o remains the most accessible entry point for general audiences due to its brand recognition and interface quality.
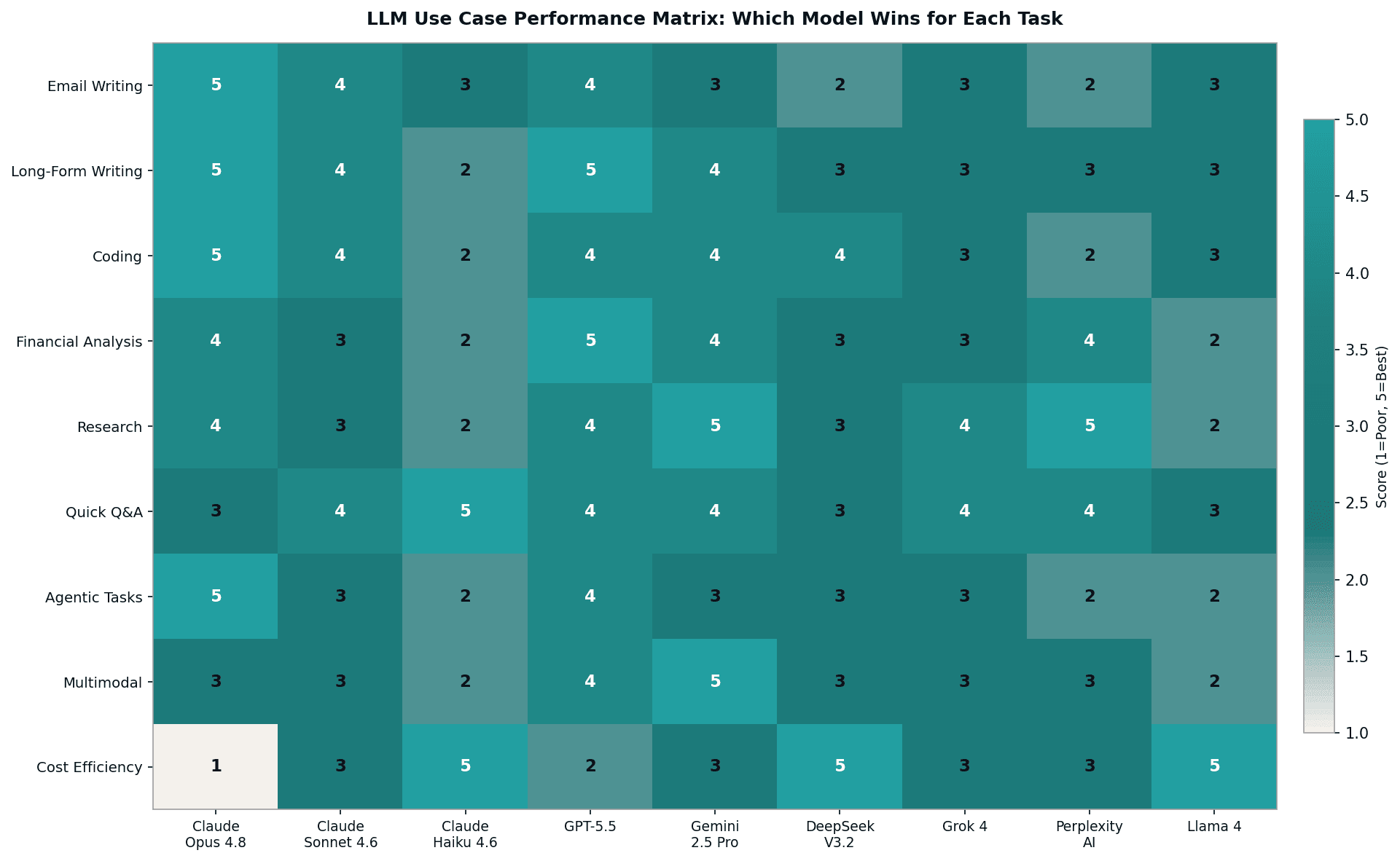
Figure 3: Performance matrix evaluating the top nine frontier models across eight critical business use cases. Scores range from 1 (poor fit) to 5 (best available option).
3. The Visual Generation Landscape
Image generation has fully diverged into specialized engines. The choice of generator now depends entirely on the creative brief, and selecting the wrong tool for a given visual requirement produces results that are noticeably inferior to the category leader.
Photorealism and Product Photography
Flux 2, developed by Black Forest Labs, is the current benchmark for photorealistic generation. Built by former Stability AI researchers, it resolves the anatomical and textural issues that plagued earlier models, delivering superior skin rendering and accurate lighting interactions. For lifestyle imagery, product visualization, and architectural photography, Flux 2 operates at a higher ceiling than any competitor. Its prompt adherence on complex multi-element compositions is also the strongest available.
Text Rendering and Enterprise Fidelity
When a brief requires legible, accurate text rendered directly into an image, Google Imagen 4 is the clear leader. It handles complex typography and brand-safe enterprise requirements better than Flux or Midjourney. Ideogram v3 is the closest alternative for text-heavy visual briefs. This distinction matters significantly for marketing teams producing ad creative where headline legibility is non-negotiable.
Artistic Direction and Stylization
Midjourney v7 remains the premier tool for expressive, highly stylized, and illustrative output. While it lags behind Flux 2 in raw photorealism, its aesthetic coherence and community-driven art direction make it the default choice for concept art and creative exploration. The model's strength is in producing output with a distinctive visual identity, which is precisely what photorealistic models sacrifice in pursuit of accuracy.
Brand Safety and Commercial Licensing
For enterprise marketing teams requiring strict commercial safety, Adobe Firefly 3 is the only viable option. Trained exclusively on licensed and public domain content, it removes the copyright ambiguity associated with open-weight models. The tradeoff is creative range: Firefly's output is competent but lacks the ceiling of Flux or Midjourney for purely creative work.
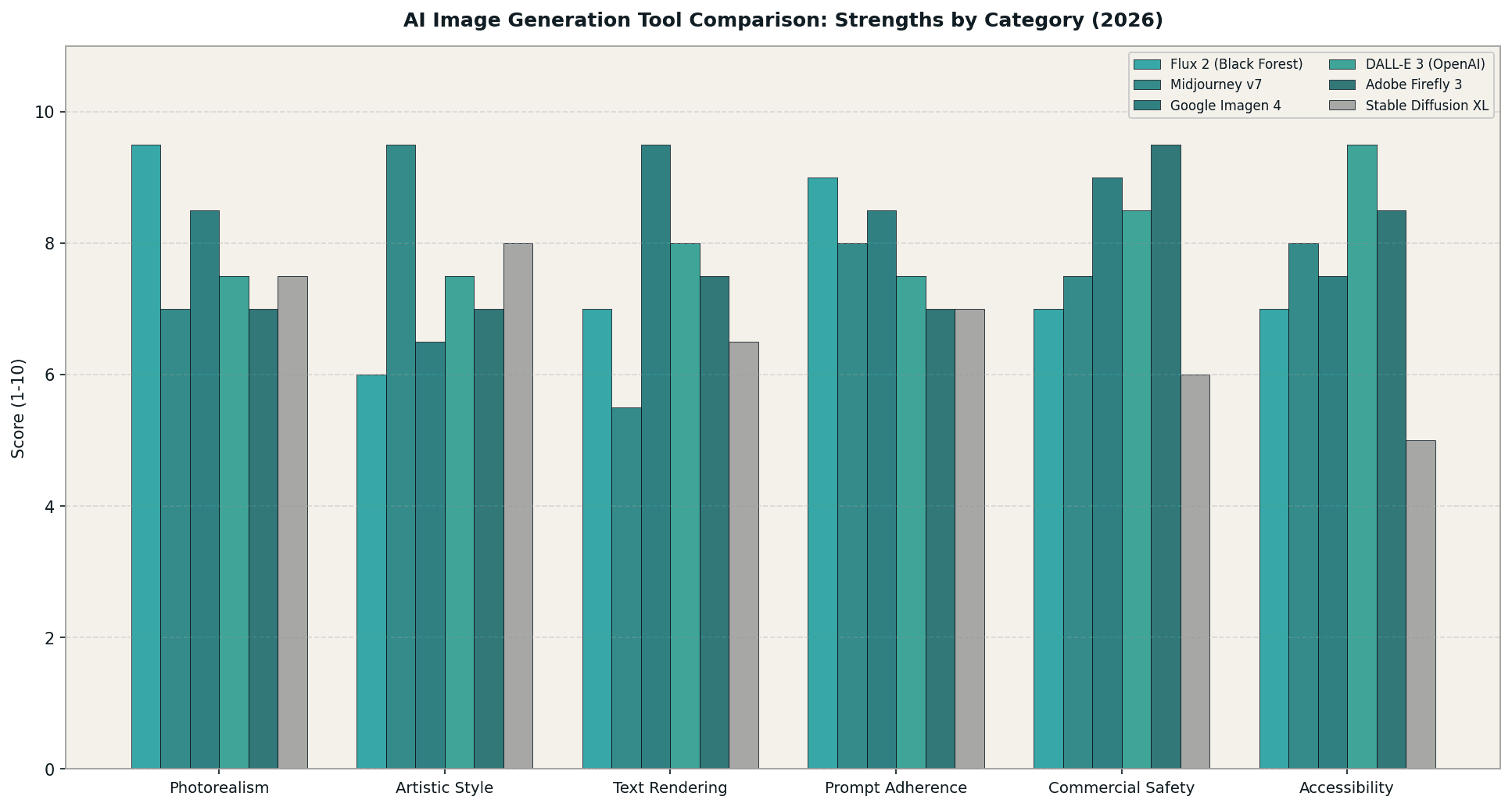
Figure 4: Comparative strengths of the top six image generation models across six key dimensions. Each model leads in a distinct category, reinforcing the case for a multi-tool approach to visual production.
4. Speed, Intelligence, and the Economics of Scale
The final variable in the 2026 AI equation is economics. Frontier models like Opus 4.8 and GPT-5.5 carry premium inference costs. Deploying them for basic summarization or simple data extraction is financially inefficient. The most sophisticated AI operations in 2026 use intelligent routing: directing high-complexity tasks to premium models and high-volume, lower-complexity tasks to cost-optimized alternatives.
Open-source and highly optimized models have closed the gap for routine tasks. DeepSeek V3.2 offers remarkable reasoning capabilities at a fraction of the cost of commercial APIs, making it the preferred choice for cost-sensitive deployments and developers who require full control over their inference stack. Meta's Llama 4 provides a powerful, privacy-first option for teams capable of self-hosting, with performance that competes with commercial models on many standard benchmarks.
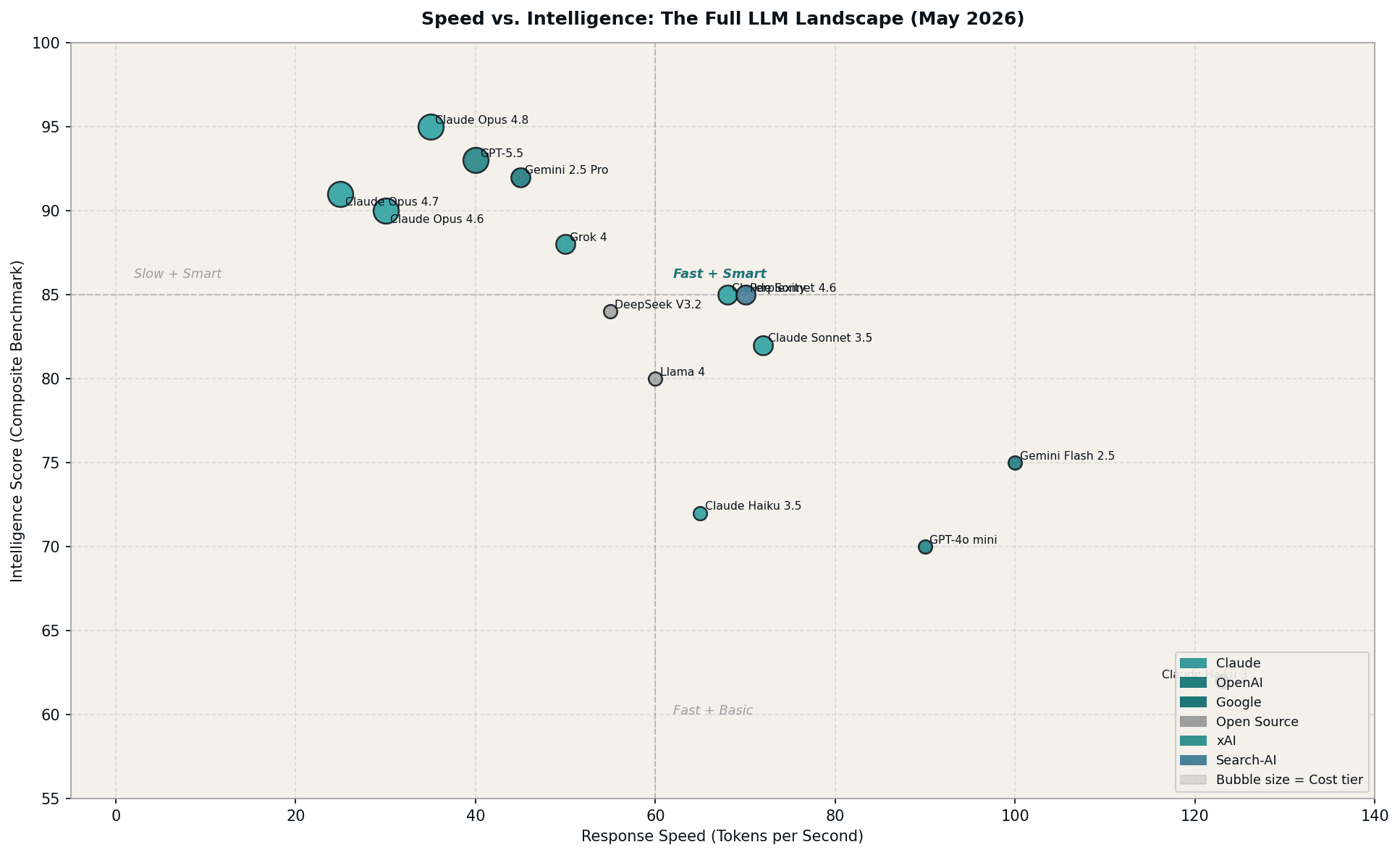
Figure 5: The tradeoff between response speed and composite intelligence across the current LLM market. Bubble size represents cost tier. The upper-right quadrant represents the optimal zone for high-throughput, high-intelligence workflows.
| Model | Developer | Best Single Use Case | Speed | Cost Tier | Standout Benchmark |
|---|---|---|---|---|---|
| Claude Opus 4.8 | Anthropic | Agentic tasks, deep writing | 35 TPS | Premium | Super-Agent: 100% completion |
| Claude Sonnet 4.6 | Anthropic | Coding at scale | 68 TPS | Mid | SWE-bench: 79.6% |
| Claude Haiku 4.6 | Anthropic | High-volume quick tasks | 65 TPS | Low | Fastest Claude for cost |
| GPT-5.5 | OpenAI | Financial and professional analysis | 40 TPS | Premium | GDPval: 84.9% |
| Gemini 2.5 Pro | Multimodal and long documents | 45 TPS | Mid | Best multimodal context | |
| DeepSeek V3.2 | DeepSeek | Cost-sensitive coding | 55 TPS | Very Low | $0.04/M tokens |
| Grok 4 | xAI | Real-time information tasks | 50 TPS | Mid | X/Twitter integration |
| Perplexity AI | Perplexity | Research and fact-checking | 70 TPS | Low-Mid | Real-time web synthesis |
| Llama 4 | Meta | Privacy-sensitive deployments | 60 TPS | Free (self-host) | Open source leader |
5. The Power User Quick Reference
For avid AI users who need a fast decision framework, the following guide covers the most common workflow questions. The goal is not to memorize every benchmark but to build intuition for which tool to reach for first.
| Task | Best Tool | Runner-Up | Why |
|---|---|---|---|
| Writing an email | Claude Opus 4.8 | Claude Sonnet 4.6 | Best tonal nuance and human-sounding prose |
| Writing a long report or paper | Claude Opus 4.8 | GPT-5.5 | Sustained quality across long sessions |
| Coding a new feature | Claude Code (Opus 4.8) | Cursor | Leads CursorBench at 70% |
| Financial modeling | GPT-5.5 | Gemini 2.5 Pro | Leads GDPval benchmark at 84.9% |
| Researching a topic | Perplexity AI | Gemini 2.5 Pro | Real-time web synthesis with citations |
| Quick question or casual chat | Claude Haiku 4.6 | Gemini Flash 2.5 | Fast, cheap, capable for simple tasks |
| Analyzing a PDF or chart | Gemini 2.5 Pro | Claude Opus 4.8 | Best multimodal context window |
| Automating a multi-step workflow | Claude Opus 4.8 | GPT-5.5 | Leads Super-Agent benchmarks |
| Generating a photorealistic image | Flux 2 | Google Imagen 4 | Best photorealism and prompt adherence |
| Generating artistic or stylized art | Midjourney v7 | Stable Diffusion XL | Best aesthetic coherence |
| Text in an image (ads, banners) | Google Imagen 4 | DALL-E 3 | Best text rendering accuracy |
| Brand-safe marketing visuals | Adobe Firefly 3 | Google Imagen 4 | Fully licensed training data |
| Privacy-sensitive tasks | Llama 4 (self-hosted) | DeepSeek V3.2 | No data leaves your infrastructure |
| Lowest cost at scale | DeepSeek V3.2 | Claude Haiku 3 | $0.04/M tokens, strong reasoning |
Conclusion
The era of the monolithic AI assistant is over. The most effective professionals in 2026 do not rely on a single chat interface. They route their workflows through specialized models, matching the tool to the exact requirements of the task. Whether leveraging Opus 4.8 for complex reasoning, GPT-5.5 for structured analysis, or Flux 2 for photorealism, the competitive advantage belongs to those who understand the specific strengths and limitations of the entire frontier landscape. The Opus 4.7 controversy is a useful reminder: even within a single model family, version differences can be significant enough to change the optimal choice for a given workflow.
References:
[1] Anthropic - Claude Opus 4.8 Release Notes - https://www.anthropic.com/claude/opus
[2] OpenAI - Introducing GPT-5.5 - https://openai.com/index/introducing-gpt-5-5/
[3] MindStudio - Claude Opus 4.7 vs Opus 4.6: What Actually Changed - https://www.mindstudio.ai/blog/claude-opus-47-vs-46-what-changed/
[4] TeamAI - Claude Models Compared: Pricing, Speed & Which to Use - https://teamai.com/blog/large-language-models-llms/understanding-different-claude-models/
[5] Zapier - The best large language models in 2026 - https://zapier.com/blog/best-llm/
[6] Cliprise - Best AI Image Generator 2026: Tested Rankings - https://www.cliprise.app/learn/comparisons/features/best-ai-image-generator-2026-tested-ranked
[7] Hacker News - Opus 4.7 long-context retrieval regression - https://news.ycombinator.com/item?id=47794961
[8] Vellum - Everything You Need to Know About GPT-5.5 - https://www.vellum.ai/blog/everything-you-need-to-know-about-gpt-5-5
Published by Tiger Tracks. Eye of the Tiger Intelligence Series.
Eye of the Tiger
Get our research in your inbox
Strategic research and tactical playbooks for operators and investors. No spam, unsubscribe anytime.
Tiger Tracks • tigertracks.ai
